
前兩天我們反覆地強調,在一個 OLTP 系統,高度符合正規化設計,且具備一定業務量的資料庫裡,要取得合用的分析資料,需要付出不少代價,包含業務受影響、查詢效能差等等。於是得有人把資料從原始的位置搬進 OLAP 系統裡,創造決策與分析的價值。
那個人是資料工程師,搬運的動作則稱為-建立資料管線 (Data Pipeline)
Data Pipeline 是指一系列的資料處理步驟,包括以下幾個階段:
*為了方便說明,我們把清理與轉換統稱為 T。
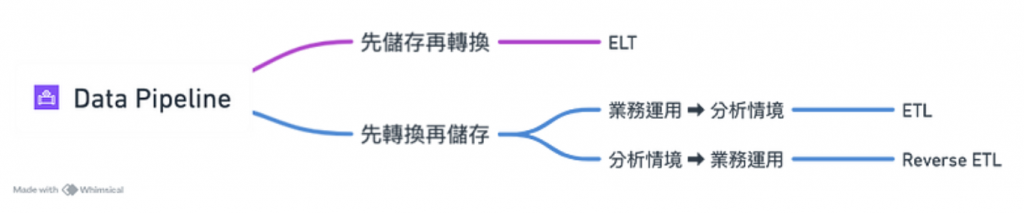
圖/資料處理步驟及運用的可能組合。簡書廷製。
資料收集 (E) 完成後,可以根據資料運用的期待決定儲存 (L) 與轉換 (T) 的順序。
先轉換再儲存稱為 ETL,這個流程有著以下優勢:
先儲存再轉換稱為 ELT,這個流程的特性優勢:
兩個流程的優勢正好就是對方的劣勢。如 ETL 流程就很容易因為分析需求的改變,需要頻繁修改轉換邏輯,容易成為開發瓶頸。但 ELT 流程就需要較大的儲存空間來保存所有資料,為了消化不同型態的資料,data pipeline 初始建置時間也可能較長。
不過,因為雲端技術的成長,靜態資料儲存成本相較於資料轉換成本而言更低,當團隊有時間餘裕時,通常會傾向使用 ELT 流程,過了初始建置期後,帶來的運用效益較高,也較不容易有後續轉換邏輯的開發瓶頸。
你也許注意到了,有個 Reverse ETL 好像沒有被講解到,下段立刻分解!
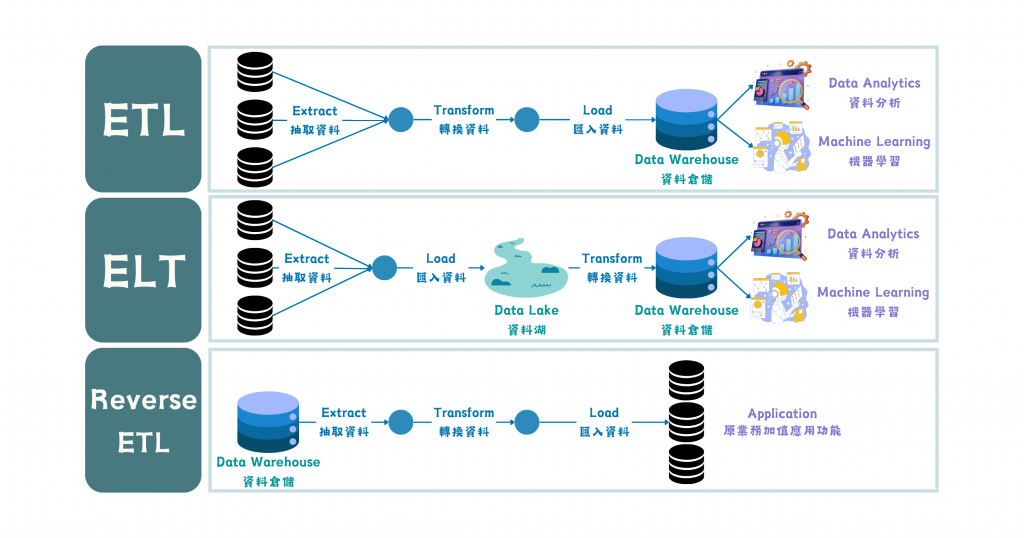
圖/Data Pipeline 的不同運用場景。簡書廷製。
把前段提到的 ETL 與 ELT 對應到的資料流轉情況繪製成圖,可以發現 data pipeline 最尾端的資料倉儲 (Data Warehouse, 也是個 OLAP 系統) 裡面儲存的結構化資料都會提供給資料分析和機器學習使用。換言之,資料分析師與機器學習工程師是資料的消費者 (consumer),在光鮮亮麗的模型 (modeling) 與儀表板 (dashboard) 背後,在後方擔任原料運補的人則是資料工程師。
一般的資料流向是從業務運用流向分析情境,剛剛沒提到的 Reverse ETL 則是將資料反向運用,例如我現職公司 SHOPLINE 在顧客分眾發送購物金/優惠券或是 EDM 行銷工具 SmartPush 都屬於這樣的運用。背後的原理就是把資料從資料倉儲再次 ETL 加工送入應用端,讓應用程式 (Application) 取用。

圖/在壯麗巍峨的大樓工程背後,有著一群建立管線輸送資源的人。Generated by Adobe Firefly。
還記得副標『Data Engineer 與合作夥伴如何譜出協奏曲』嗎?
後端工程師:『你在做的事情,是不是跟我在開發應用程式裡面的 CRUD 有點像?我是不是也能夠做到?』
資料工程師:『如果資料量夠小的話,你就全包了吧!』
再一次強調,這些資料工程的流程與手法,都是基於一定程度的資料量所衍生的。如果業務情境相當單純,規模也不大的時候,這些概念都很難接觸到。
資料分析師 & 機器學習工程師:『為什麼我們只是要改一個欄位的定義,你卻說要花很多心力?』
資料工程師:『如果你能在需求定義時想的更清楚,我們就能更專心的在彼此的專業上努力。另外,給我們一些時間把初期的環境建置弄完整吧!』
調整欄位本身不是困難的,但頻繁地調整就是困擾了。當然有很多現代資料技術 (Modern Data Stack) 可以有效提升我們在開發/維護 Data Pipeline 的效率,不過我相信確實定義需求還是不變的合作真理。
衷心希望我的文章能深入淺出地,帶給不是真的有資料工程經驗的夥伴一些些啟發甚至相互體諒。
今天的資訊量夠多了。明天我們再來談上面的流程中,沒解釋到的那片湖泊以及那座倉庫吧!

